
在這裡,你可以盡情揮灑你的想像力,不覺得這很令人難以想像嗎?
《芝麻街》Elmo
在過去幾天的旅程中,我們了解如何利用各種神經網路模型來幫助我們處理不同自然語言處理任務,計算語言學家接著也基於前面講過的那些神經網路模型,陸續發展了許多其他新型態的語言模型,例如:基於BiLSTM的ELMo。我想應該是研究太苦悶了,或者說是一種惡趣味吧?自然語言處理專家特別喜歡用芝麻街的角色來為這些語言模型命名,就算是硬湊名稱,也要把它湊成芝麻街角色的名字(e.g. 今天要介紹的 BERT 就是一個案例)。假如說,現在小小孩想上網抓 Elmo 的照片,結果卻出現一堆莫名其妙的節點跟線的連接圖,會被嚇哭吧? 計算語言學家都是邪惡的。
不過如果你還有印象,就會記得 BiLSTM 儘管記憶力已經比 RNN 還要好了,但人工智慧學家對仍然不滿足,他們認為如果要了解一個字在文章中的「定位」,就必須要讓模型理解全文才能真正決定。所以接下來學者又開發出了 Transformer ,而其中的 Self-Attention 機制,使每一個字對每一個字來說「沒有位置的概念」。好,我知道有點玄,就套句台大李宏毅老師所說:
海內存知己,天涯若比鄰。
這時候,兩個有關係的字,即使離很遠,模型也能理解之間的關係。就是這樣,Transformer 的 Self-Attention 機制,就可以完全解決 RNN 系列的天生缺陷。而今天要介紹的 BERT 就是基於 Transformer 所搭建的模型。
在 2018 年時(其實沒有很久以前喔),Google 集先前所有語言模型大成,打造了 BERT,並釋出了模型及原始碼,幫助處理各式各樣的下游任務,而這個 BERT 的表現,以及準確度,都到了迄今仍無人能超越的地步。
話說得有點誇張,不過當時 BERT 模型的釋出,確確實實地撼動了計算語言學界與自然語言處理業界。在那篇被引用了四萬多次的論文(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)之中,介紹了如何用 BERT 進行兩階段的訓練方法,幫助後續自然語言的處理任務。
如果說能夠先訓練出一個對自然語言有一個大致了解的模型,並且基於這模型再針對各種不同下游任務進行調整,這種方法稱為:遷移學習(Transfer Learning)。這篇論文的作者就是為了實現這一個目標,將 Transformer 中的 encoder、大量的文本,以及針對目標進行的預訓練,來搭建整個 BERT 模型。而作者為了要達成這個目標,將訓練過程分成兩個階段:
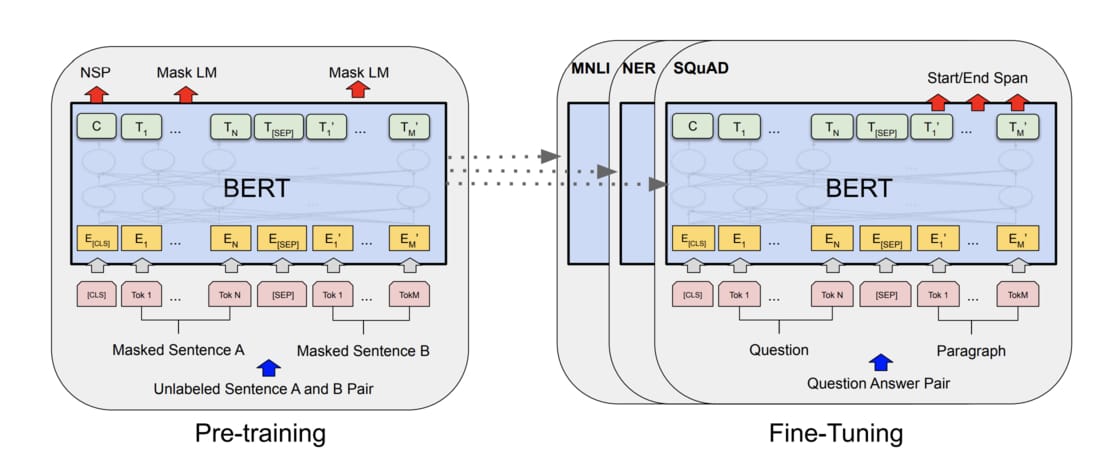
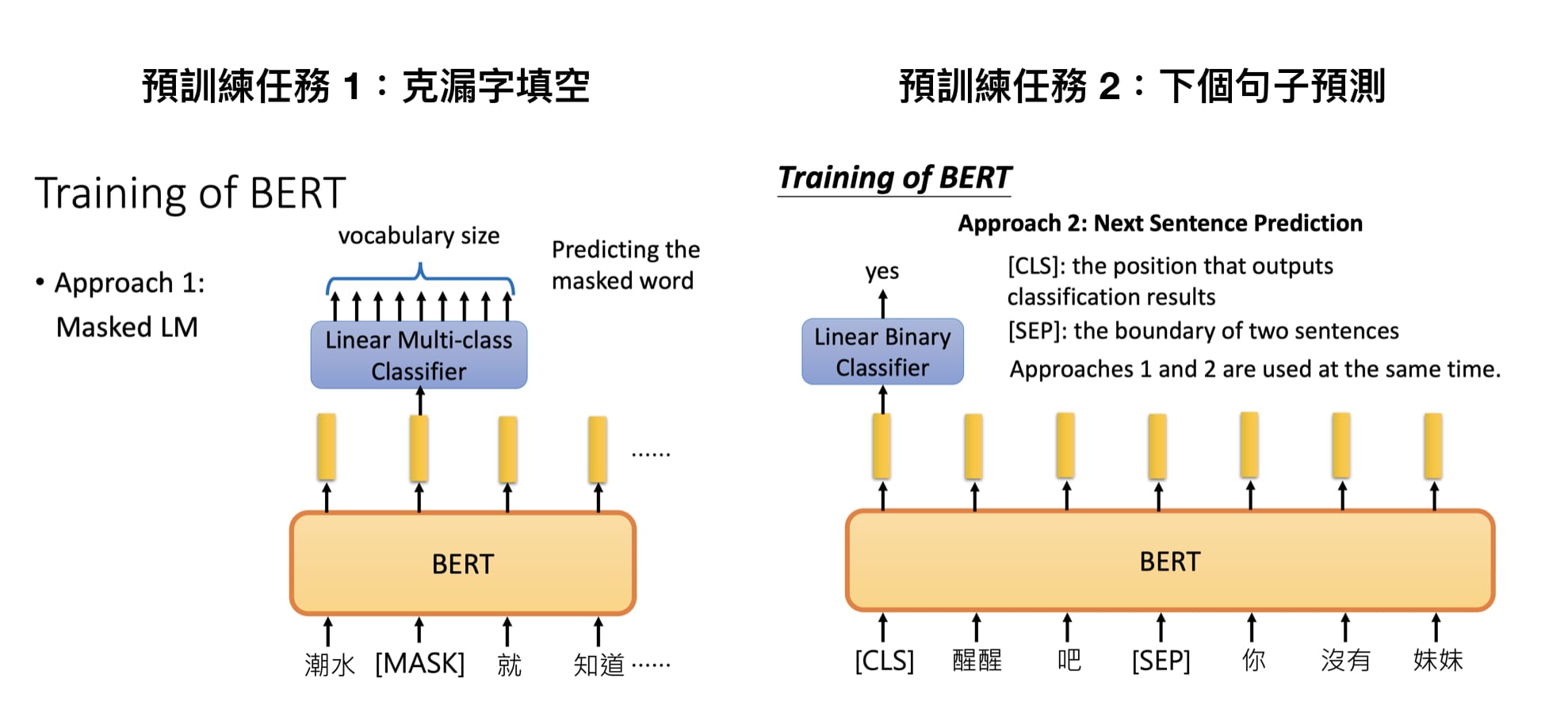
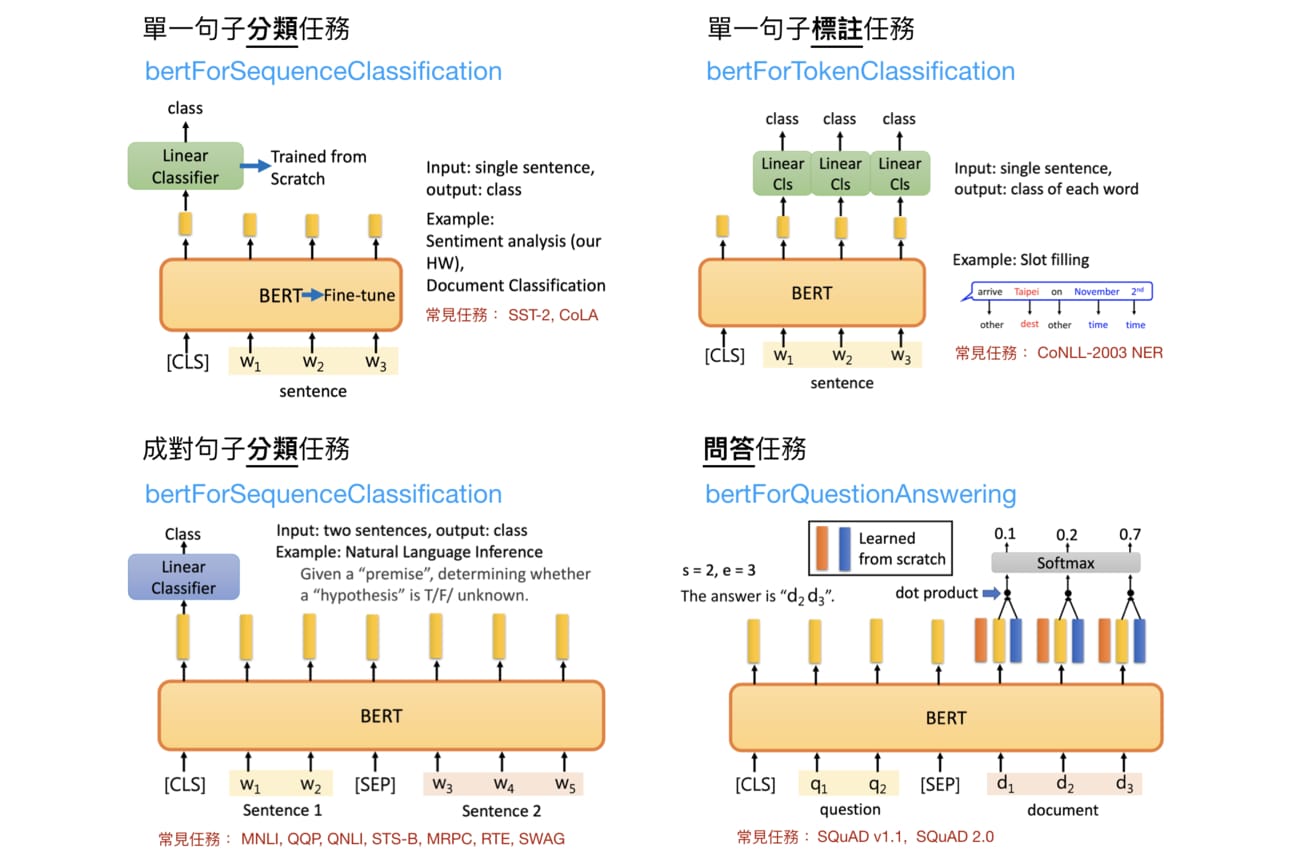
看到這邊,大家可能想說,咦?那跟先前介紹的使用 LSTM 訓練的模型,有什麼差別?好像就是個很厲害的語言模型不是嗎?為什麼好像 BERT 獲得較高的關注?不公平啊!其實使用 LSTM 訓練的模型跟 BERT 有一些結構上還有運用上的差異及差異,這就讓我們一一來看看是怎麼回事吧!
好,今天就講到這,明天就上我們拿起放大鏡,來一一了解 BERT 的訓練過程以及下游任務的應用囉!明天見。

